Leveraging Knative, Submariner and OCM at PHYSICS EU Project for multicluster orchestration
PHYSICS is a high-technology European research project with a consortium of 14 international partners, including technology producers, research centers, and universities. The main goal of PHYSICS is to unlock the potential of the Function-as-a-Service (FaaS) paradigm for cloud service providers, platform providers, and application developers, and foster its wide deployment. PHYSICS enables application developers to design, implement, and deploy advanced FaaS applications using new functional flow programming tools that leverage proven design patterns and existing libraries of cloud/FaaS components. The project started in January 2021 and will end in December 2023.
To support the above there was a need for deploying functions across different Clusters located in different locations (including edges) and making improved orchestration decisions about what functions to deploy where. Thehe project has developed different components that allows to gather important information about the different resources available and the functions themselves. These components need to be installed in different clusters and connected to each other. In the project we are using Open Cluster Management (OCM) as the main building block for multicluster management and orchestration and Submariner as a way of connecting the applications in the different cluster.
This blog post is about how we have leveraged Knative, Submariner and OCM to deploy, configure and connect those PHYSICS components across a dynamic set of Kubernetes clusters managed through OCM.
Once a (set of) cluster(s) is onboarded into OCM, the clusters can be managed from the hub cluster (i.e. the central cluster used to manage the different edges, and that contains the Submariner broker). The first step, before being able to deploy Functions in a given edge, is to configure (from the central cluster) the edge with the required PHYSICS components/applications, connecting them with the required components in the central (Hub) cluster.
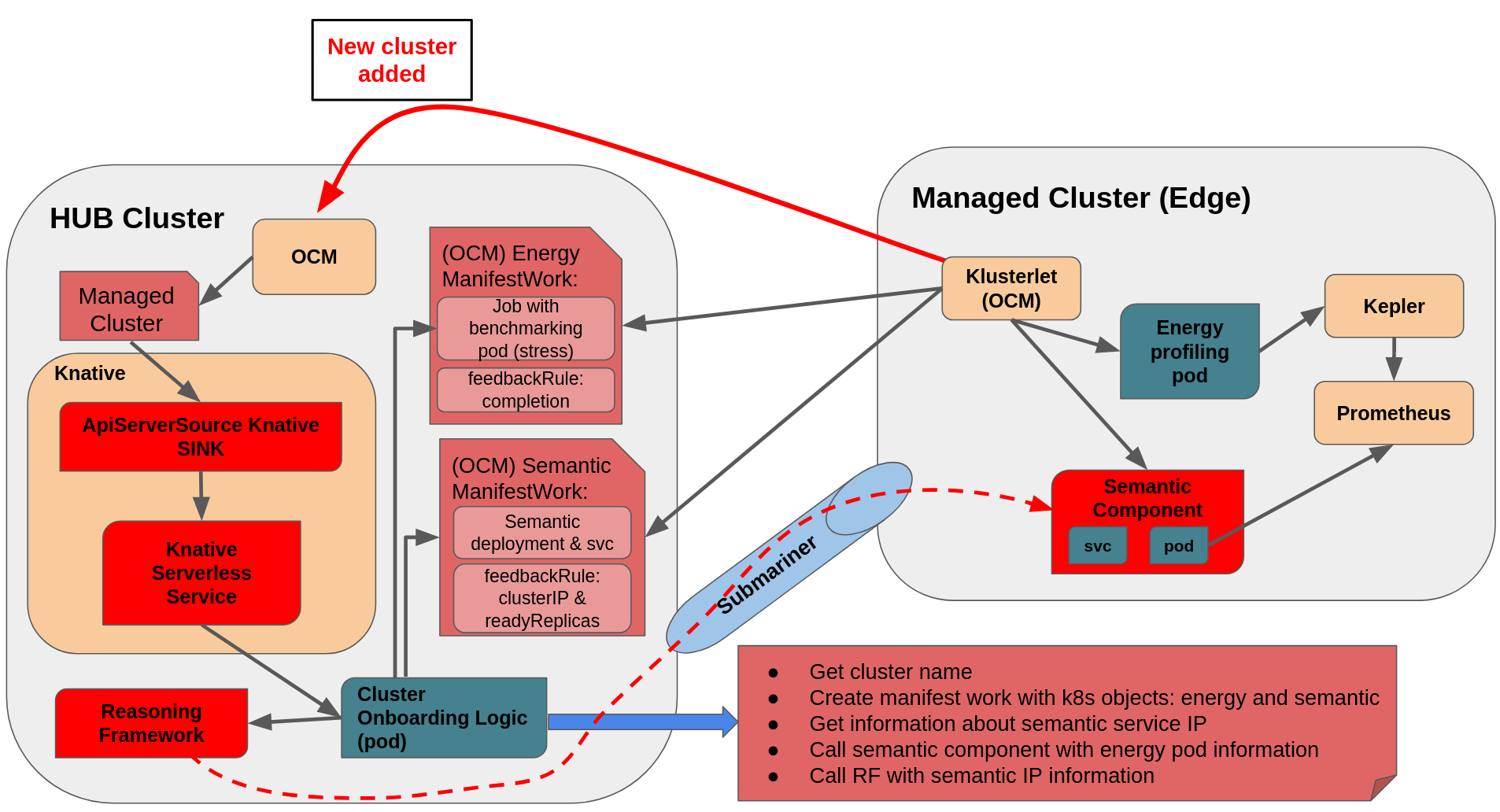
As depicted in the previous figure, the cluster onboarding mechanism is designed in a serverless fashion, using Knative eventing and serving:
- Eventing: Knative Eventing is a collection of APIs that enable event-driven architectures with your applications. We are using the Knative ApiServerSource Sink component to detect events related to cluster creation (OCM managedcluster object creation) and redirect them to their consumer (known as sinks):
apiVersion: sources.knative.dev/v1
kind: ApiServerSource
metadata:
name: api-server-source
namespace: physics-cluster-registration
spec:
mode: Resource
resources:
- apiVersion: cluster.open-cluster-management.io/v1
kind: ManagedCluster
serviceAccountName: physics-cr-sa
sink:
ref:
apiVersion: serving.knative.dev/v1
kind: Service
name: cluster-registration
- Serving: we make use of Knative services to deploy the actual logic that will consume/process the detected event. It does so in a serverless fashion to save resources: one of the cool things is that it will automatically scale to 0 as clusters are not being added all the time and we don’t need to have this running in the background:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
annotations:
app.openshift.io/route-disabled: 'true'
name: cluster-registration
namespace: physics-cluster-registration
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/maxScale: '3'
spec:
containerConcurrency: 1
serviceAccountName: physics-cr-sa
containers:
- image: quay.io/ltomasbo/cluster-registration:latest
imagePullPolicy: Always
name: cluster-registration
ports:
- containerPort: 8080
protocol: TCP
env:
- name: RF_API_KEY
valueFrom:
secretKeyRef:
name: rf-credentials
key: password
- name: RF_API_URL
valueFrom:
secretKeyRef:
name: rf-credentials
key: url
The logic inside the Knative service is the one that can be easily extended/modified to account for new/extra components/resources. It is in charge of creating the needed resources in the remote cluster, as well as gathering the required information, such as the service IPs to be used (through submariner) in the central hub components. It also performs calls to both local and remote PHYSICS components to provide the required information/configuration - again leveraging submariner networking.
As highlighted in the Figure, the API and components of Open Cluster Management are leveraged as the basis for configuring the (edge) clusters as needed. The OCM ManifestWork contains a list of Kubernetes objects to be created, and that could include not only pods, but also services, ServiceExports (for the Submariner support, to make the pods/services available across different clusters), and other specific CRDs, for instance the ones related to the PHYSICS project or the Kubernetes nodes itself.
In addition, we relies on Knative capabilities to make it event driven and serverless (saving resources as clusters are not being added all the time). The process is the next:
-
A remote cluster gets added to the Hub (as Managed Cluster) through OCM, which creates an object of type ManagedCluster
-
The Knative APIServerSource receives this event and invokes the Knative Serverless Service
-
The Knative Serverless Service receives the event and creates a new pod with the cluster onboarding logic (if there is not one already created), and once it is ready, it redirects the event to it.
-
The cluster onboarding pod process the request by:
-
Getting the cluster name
-
Creating an (OCM) ManifestWork which includes a Kubernetes Job that will generate some benchmarking load in the managed cluster. The klusterlet agent in the remote cluster is in charge of applying this ManifestWork associated to it, and create the pod with that benchmark
-
Waits until the job is completed – by using OCM feedbackRule
-
Create an additional (OCM) ManifestWork which includes the definition of the semantic deployment and its associated service. Again the klusterlet agent is in charge of creating the local resources in the remote cluster.
-
Waits until the deployment is ready and obtains its service IP - by using OCM feedbackRule
-
Makes use of submariner to call the semantic service IP and provide the information about the previous job, to be used to estimate the energy consumption and cluster performance and energy scores.
-
Calls the Reasoning framework to provide the information about the semantic service IP, so that it can start requesting semantic information from the new cluster(s).
-
Last but not least, the repository with the information and code about how to deploy and the logic is available here. Note it is easily extensible (or replaced) to add different components and/or configurations.
Acknowledgment
Part of the research leading to the work presented in this blogpost has received funding from the European Union’s funded Project PHYSICS under grant agreement no 101017047.